notes on Informed Privilege-Complexity Trade-Offs in RBAC Configuration
Today’s paper is Informed Privilege-Complexity Trade-Offs in RBAC Configuration by Jon Currey, Robbie McKinstry, Armon Dadgar and Mark Gritter. They introduce OnPar, the algorithm they created to power Vault Advisor.
The main problem here is well known to anyone managing some RBAC system: finding the right balance between fine-grained policies, applying the least privilege principle, and fewer more generic policies making it easier to manage.
Administrators must generate roles which reasonably tradeoff overall configuration complexity and least privilege, negotiating these conflicting objectives while respecting organizational constraints and ensuring continuity of necessary privilege.
The goal of OnPar is to help the administrator find the most appropriate policies to get the best acceptable trade-offs between least-privileges and configuration complexity in the context of their organization.
An explicit goal here is to try to help the administrators with their objective of eliminating unnecessary privilege. This implies each configuration needs to be evaluated against metrics relevant for both the configuration complexity, and for the security risk. To do this, the authors introduce the minimization of unnecessary privilege as a new metric.
The two objectives of minimizing unnecessary privilege and minimizing configuration complexity conflict with one another.
OnPar uses audit logs to get information about role usage. The main idea here is to build a comparison between privileges granted and privileges used, to identify permissions that are granted but could be removed and help reduce the unnecessary risk.
Metrics: Unnecessary Privilege and Configuration Complexity
The unnecessary risk is the sum of all privileges granted but not used. Each time such unused privilege is granted, we acknowledge it.
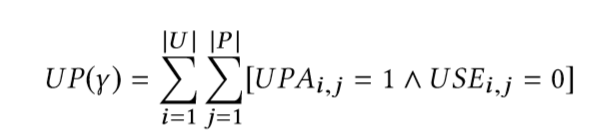
Where, U is the users list, P the permissions, UPA the user-permission assignment matrix (the current configuration) and and USE the observed user-permissions used matrix. Every time we observe a mismatch, we increment by one.
The paper highlight one interesting characteristic:
An important property of this metric is that a privilege authorized for the same user by multiple roles with overlapping permissions is only counted once.
From the perspective of the principle of least privilege, having the same permission assigned to the same user via multiple roles does not increase the risk associated with that assignment:
An attacker can exploit the privilege no more or less due to the duplicate assignment.
The configuration complexity uses Weighted Structural Complexity (1) (a sum of relationships in an RBAC state, with possibly different weights for different kind of relationships). They get the complexity score with this sum
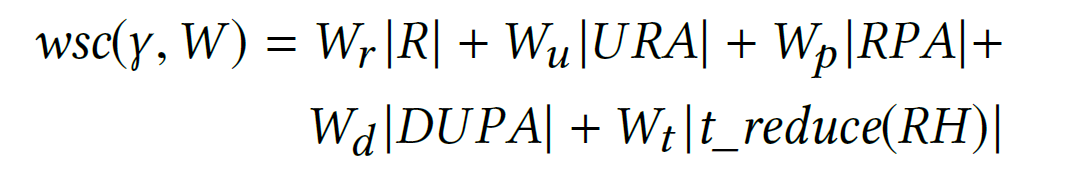
where R is the set of roles in the RBAC configuration considered, URA the set of user-role assignments, RPA the set of role-permission assignment, DUPA are permissions assigned directly to users and t_reduce(RH) the transitive reduction of the role hierarchy. The paper (and my use cases) focus on Vault, in which we don’t have DUPA or role hierarchy, which simplifies this sum with weights of 0 tor these.
This sum makes a lot of intuitive sense: the more roles you have, and the more permissions in each role you set, the more complex it becomes.
Generating many configurations
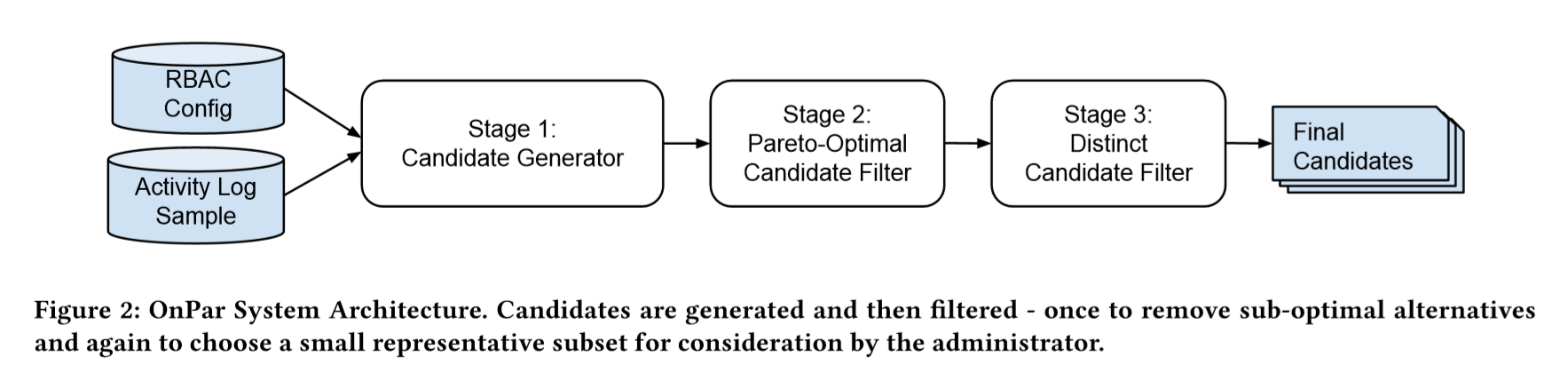
I’ll only briefly cover the candidate generator part, which aims to generate a large candidate set to explore the space of possible trade-offs between unnecessary privilege and configuration complexity, from the current RBAC configuration and the activity logs.
In short, the generator starts with the usage information to create policies, then merges them in clusters and evaluates both the unnecessary privilege and complexity scores for each solution.
Use of a Pareto optimal filter to reduce the number of choices
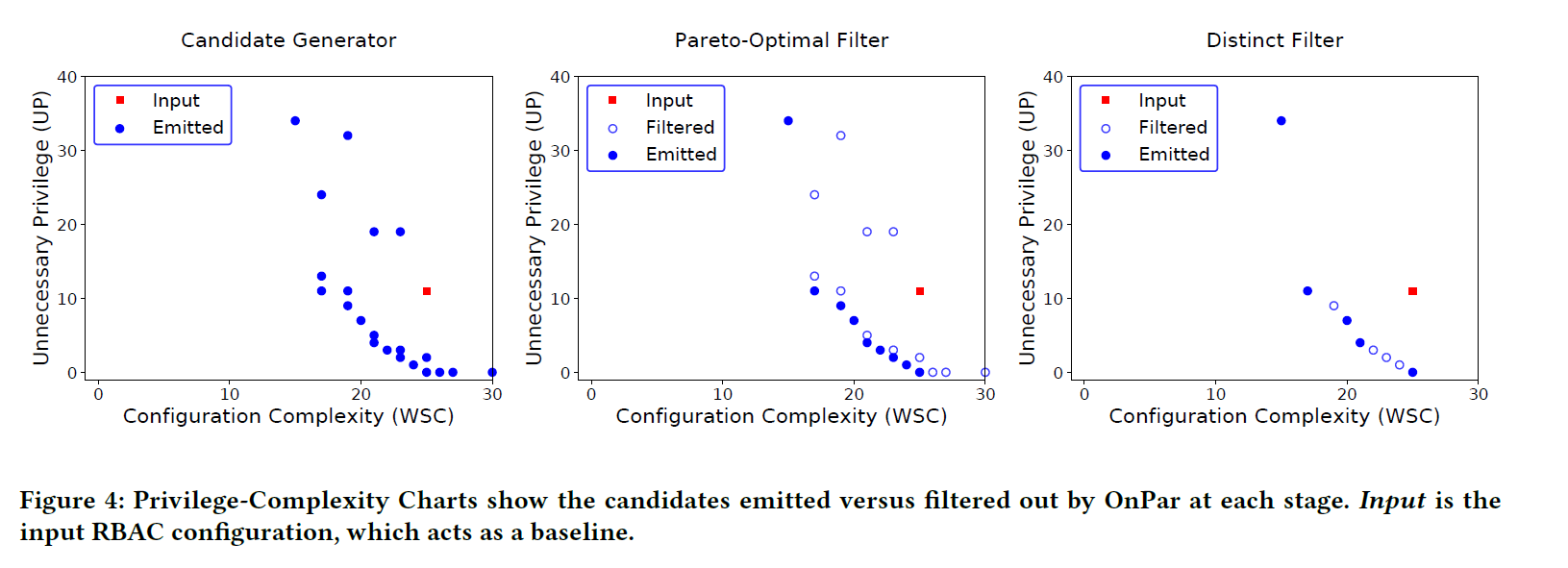
Some configurations will be more complex and will present more unnecessary privileges than other ones. We can drop these immediately.
Then, some configurations might have the same level of unnecessary privilege than another, but be more complex. We can obviously drop the second one.
This filtering reduces the number of configuration without sacrificing any trade-off.
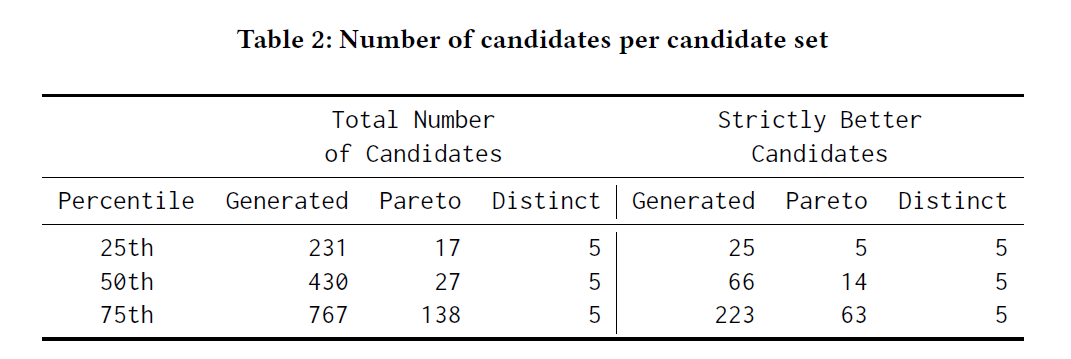
A distinct filter to keep few configurations presenting a variety of solutions
After this first filter, the system has many interesting configurations. Since the goal is to offer only a few relevant candidate configurations to a human operator who will evaluate which trade-offs are the best for his specific context, another filter is applied to keep only a small number of candidates.
The goal of this phase is to select a small number of candidates (μ) from the full Pareto front such that they still represent the variety of trade-off possibilities presented by the full front.
For this filter, they use a hypervolume indicator to measure the contribution of each candidate configuration and keep only the μ relevant ones.
Having selected a reference point, OnPar calculates the hypervolume indicator h0 of the points on the Pareto front. h0 serves as a baseline for measuring loss as candidates are removed from the front. The μ points which maximize the hypervolume indicator are then identified.
Visually, this gives plots like this. The plot which maximize the shaded area is the one with the best candidates.

The end of the paper covers the evaluation methodology and results.
The last word
I’d love to be able to see OnPar applied to the systems I manage and discover the trade-offs it would propose! The approach sounds exciting and promising.
I’m curious though about the important edge cases we have in real-life systems.
Our systems always have hardly ever used policies that we must keep. I’m curious to see how the recommendation only based on usage would deal with such permissions.
An example would be an operator who can generate a disaster recovery operator token in Vault, to be able to promote a disaster recovery cluster. That’s a permission you don’t use every day. Yet you want to make sure it’s not flagged as an unnecessary risk and be removed.
Could the OnPar approach be combined with some intent declaration, like adding annotation or metadata in policies to mark a few ones as «we know what we’re doing here». It could populate an ignore-list of privileges that OnPar would keep unchanged.
I would also be love to see how we can use it in real life. As an operator, the metrics used by OnPar are very interesting, but aren’t enough to let me evaluate the proposed configurations:
- the complexity is obviously interesting. Nobody wants to manage only many gigantic policies;
- the unnecessary privilege is exciting, even for the current configuration, and helps a lot gauge each proposed configuration;
- the removed privileges would also be very useful to help us identify the change. Exactly like how a diff helps a lot when you do a code review, and you look at the final result and at the diff to estimate the contribution. I would need to see which privileges a given configuration removes from a given user, to see if it makes sense or if it’s one of the rarely-user-but-required permission. Without such visibility, I’m not sure I would be confident enough before applying any recommended configuration on real systems.
And I could not finish my notes about this paper without referencing an excellent talk Jon and Robbie, authors of the current paper, who gave two years ago and brilliantly presented the work in progress we now know as OnPar. This talk introduces the first two-third of the flow, and I was happy to read the paper to learn more about the last filter.
-
Molloy, Ian, Hong Chen, Tiancheng Li, Qihua Wang, Ninghui Li, Elisa Bertino, Seraphin Calo, and Jorge Lobo. 2010. “Mining Roles with Multiple Objectives.” ACM Transactions on Information and System Security 13 (4). https://doi.org/10.1145/1880022.1880030. ↩︎