notes on Distributed Control Systems, a Pattern Language Approach
Today’s post covers an unusual book: Distributed Control Systems, a Pattern Language Approach, by Eloranta, Koskinen, Leppänen and Reijonen 1.
This book is not the software design book we’re used to: it’s focused on control systems for industrial systems. Industrial is the key differentiator here. Think of forest harvester, log truck, mining drills and machinery like that.
These systems have a different set of constraints than the ones we see in classical back-end software design.
That’s why I started with ‘unusual’.
Unusual implies a context: it feels unusual for me, as I spend most of my time working on back-end systems. I haven’t touched low-level hardware or electronics for many years. The last time was when building kiosks and early multi-touch tables for museums. Almost another career and another life, on another continent.
Every time I use ‘we’ hereafter, I think of colleagues and other people working on similar systems.
But when I read it, I understood why it was highly recommended: although the application domain is quite different, the parallels we can draw are apparent, and it’s refreshing and thought-provoking to see some of our shared problems presented from a different standpoint.
The patterns illustrated are often very similar from some we are used to, but with a different presentation, and the focus might not be on the same properties.
I’ll show examples of that below.
It introduces us to some less-traditional (for us, back-end developers) way to see the challenges, and forces us to step back and revisit some patterns from a different angle.
It’s very refreshing!

Organizing patterns as sub-languages
The book proposes a pattern language, and I loved this approach.
The authors use this language as we use a natural language: it helps us categorize relationships between objects and concepts.
Because they present many patterns: 80 in the book, they decompose this in sub-languages, and each section presents a sub-language, which is a fancy way to illustrate the relationship between the patterns.
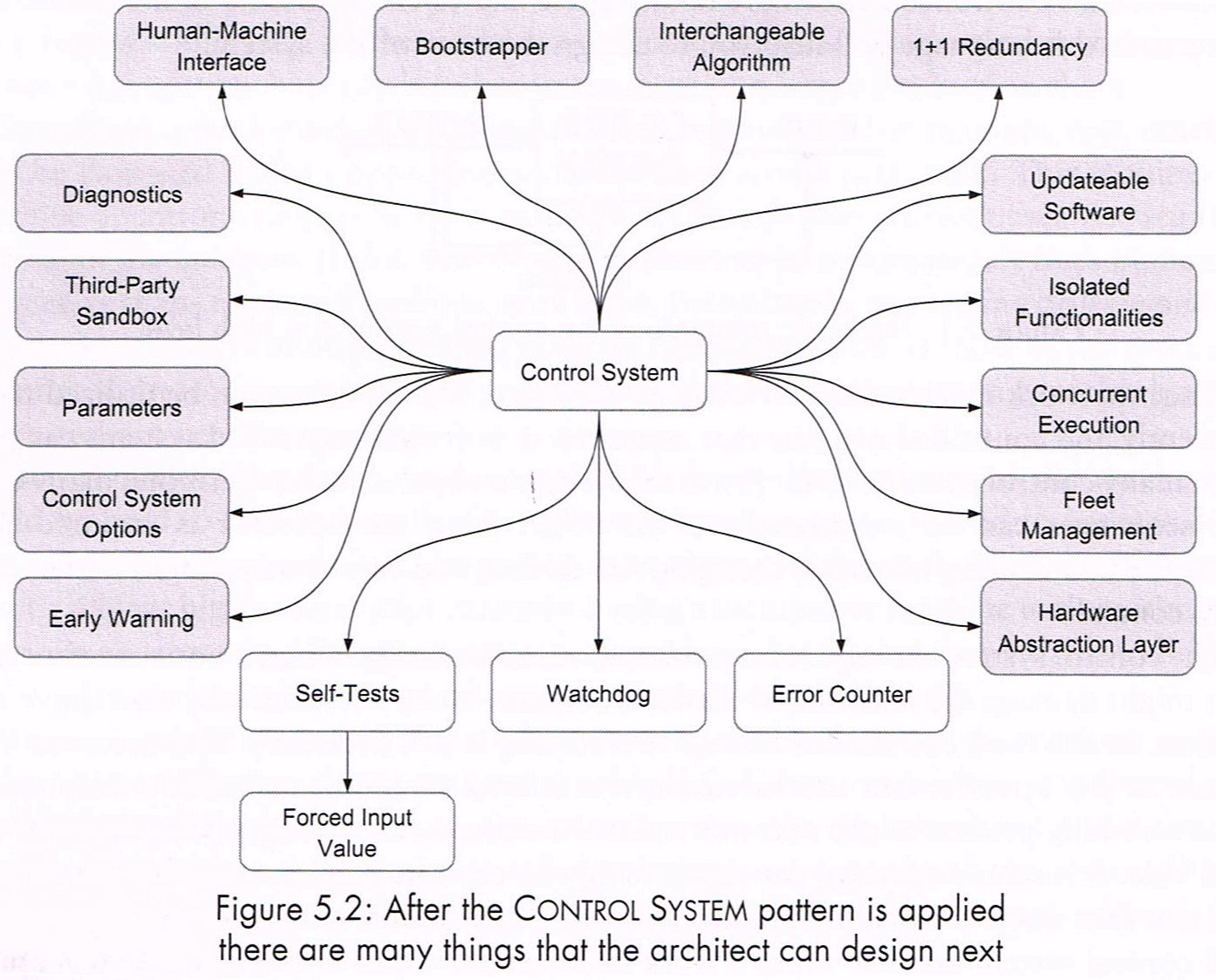
The top-level language of Control Systems patterns
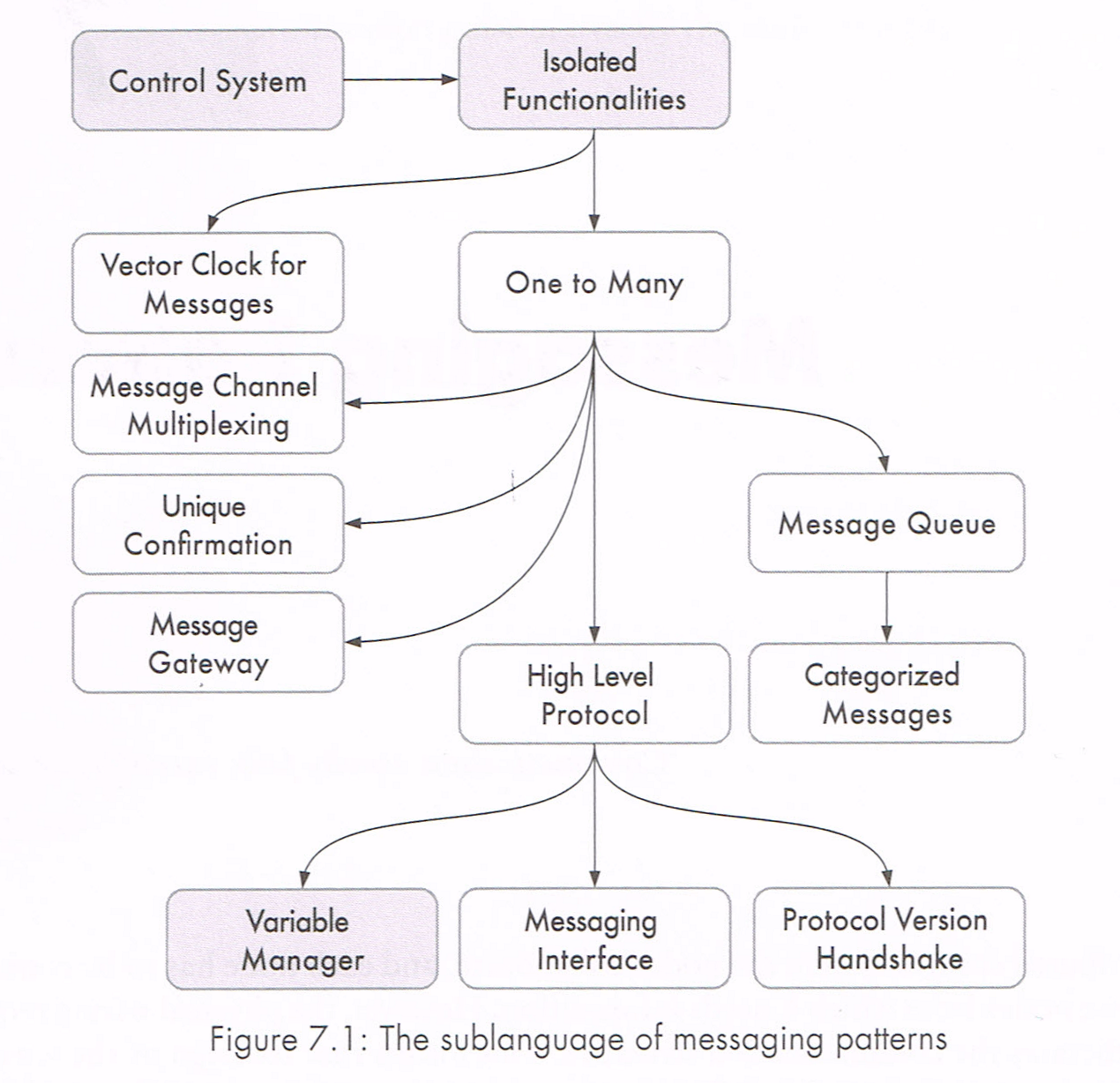
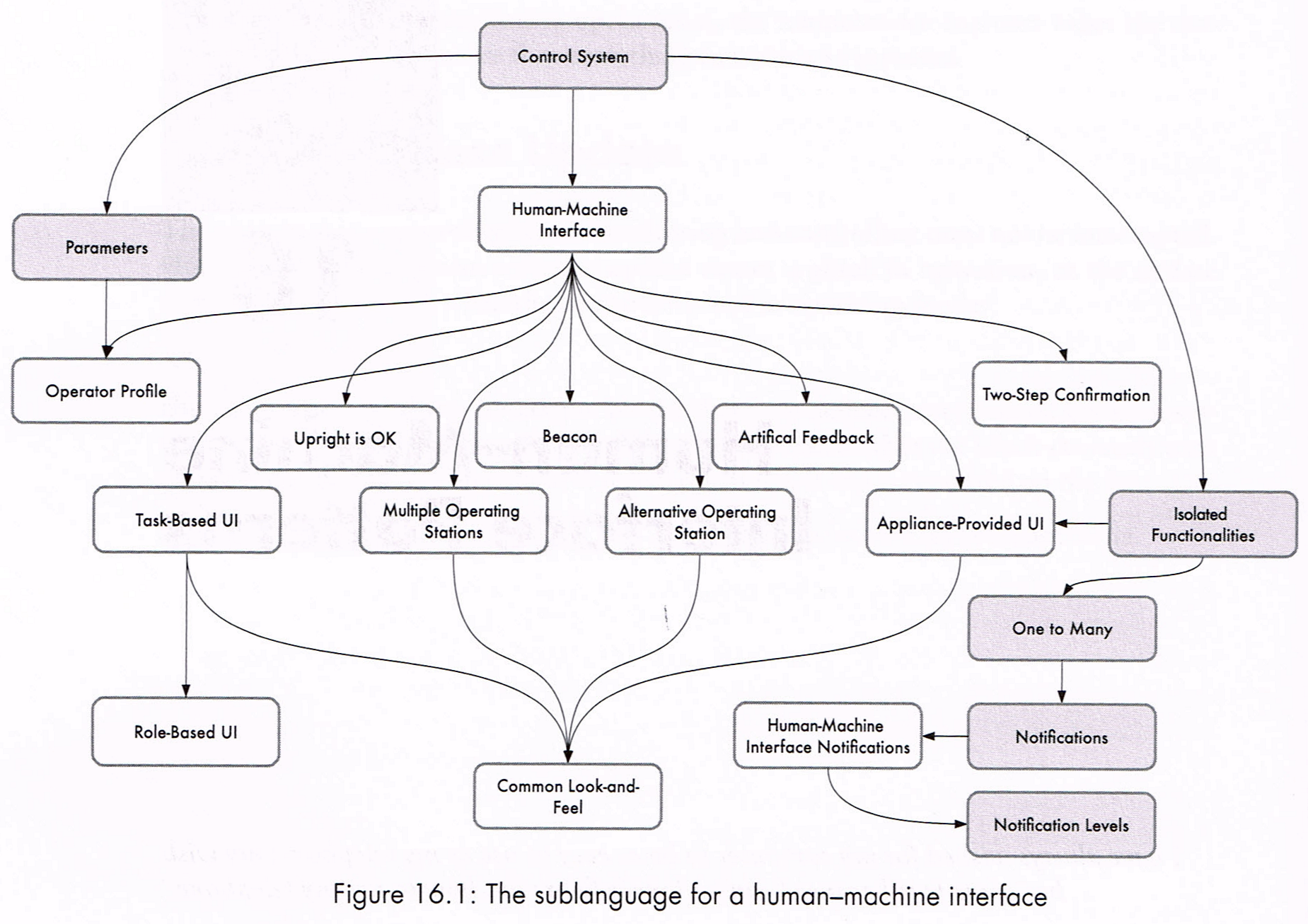
There’s no silver bullet, and a narrative helps you understand the trade-offs
We know that we do use combinations of patterns. Some work very well together, and some are unrelated. This book presents the relationships between each pattern, within and across sub-languages, in a powerful narrative and easy way.
Most of the patterns are introduced by some context description, which is key to understanding when this pattern is useful, and its consequences.
There’s no such thing as a silver bullet, and it’s advantageous to put the trade-offs under the spotlight.
The book dedicates all the Appendix A to a huge quality attribute table, which list, for each pattern, the positive and/or negative impacts on each quality attribute. An obvious example is 1+1 redundancy, which as a positive impact on fault tolerance, but a negative impact on cost-effectiveness. But many are much more subtle than this easy one.
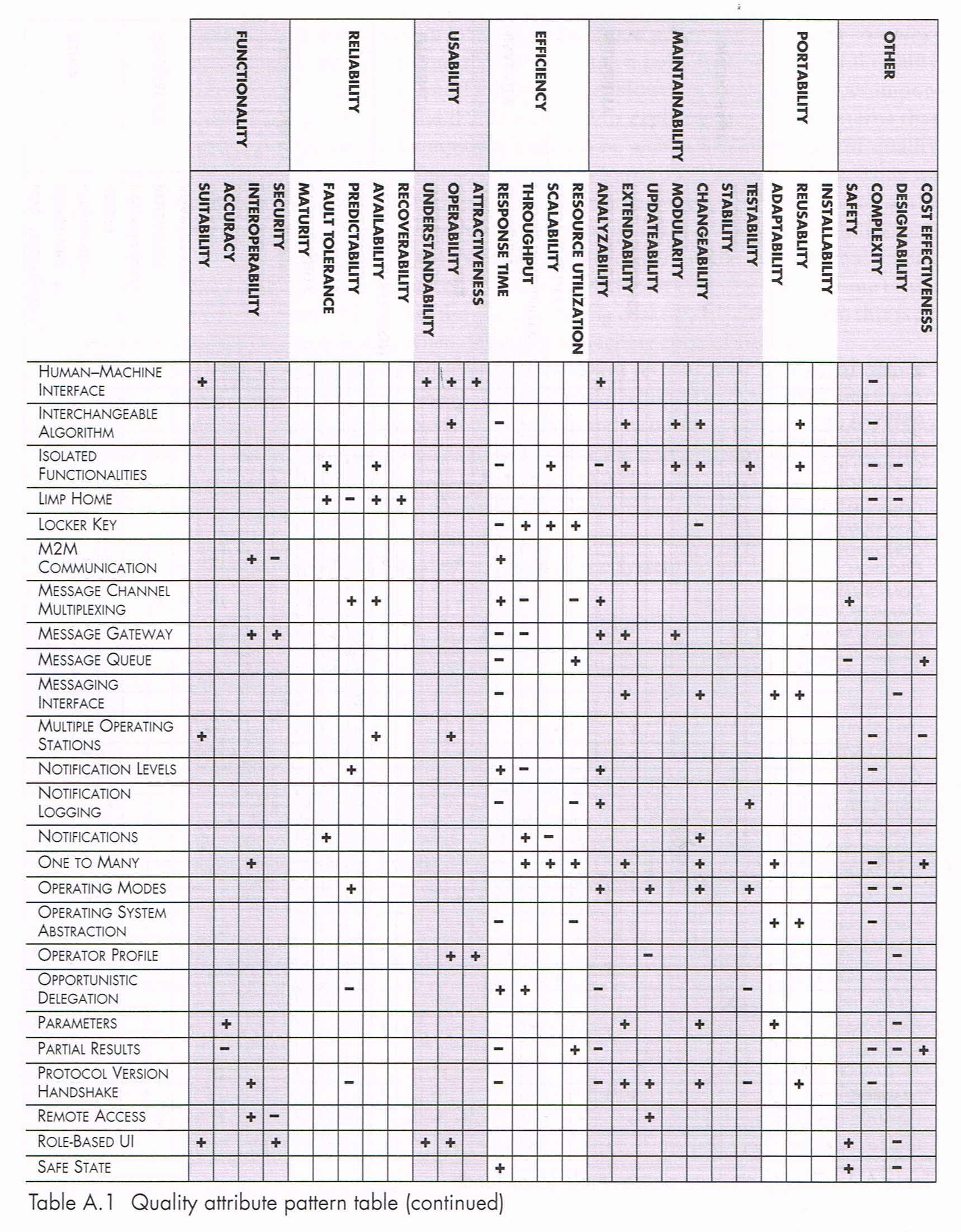
Appendix A (extract): quality attribute effects of some patterns
A few selected highlights
My goal here is just to give you a glimpse into how the book approaches this, with a few selected examples.
Hopefully, this will make you want to read more!
One thing I enjoyed was the refresher on fault tolerance in the Characteristics of Distributed Control Systems chapter (p 29).
We know that redundancy helps a lot. But the clean categorization of redundancy presented here forced me to remember things we forget
There are several approaches that can be taken to provide fault tolerance. For example at the design level, redundancy is a common approach to fault tolerance (Avizienis, 1976). In space redundancy, redundant backup components are introduced to the design that are only used when a fault occurs. (…) For information redundancy, the same information is computed in several places and a voting (link to the pattern) mechanism is used to determine the correct result, whereas in time redundancy the same unit does the same calculations several times and the results are stored for later comparison. (…) This diversity will decrease the probability of systematic failure.
A manifesto for control system development
This part, focus on software versus hardware, touched a point close to my heart.
When you have your organizational values in place, you will obtain greatest benefit from the patterns in this book.
System thinking over local optimization. Any control system should be thought of as whole and optimized as a whole, not locally on separate hardware or software levels. (…) Openness over proprietary solutions. (…)
Face-to-face communication over comprehensive documentation. (…) The software team relies on several other teams(…). Transferring domain knowledge is challenging. Unfortunately, a document is generally an inefficient and one-way form of communication. If you have over 100 pages of architecture documentation, it will most likely be ‘write-only’ documentation - that is, never read by its intended audience. So, use face-to-face communication to transfer at least some of this knowledge to subcontractors, other teams and newcomers. Document only the things that absolutely need to be remembered.
Everybody, early on, altogether. (…) Cross disciplinary teams are required to work together towards a shared goal. Involve everybody, early on, altogether, as described in Lean Architecture for Agile Software Development.
Another great quote I love from the What is Quality section (chapter 3.1, p73):
The user should not feel frustrated when using the software. This is usually achieved when the software can accurately match the mental model of the user. For the developer, however, the architecture makes all the difference. The developer feels less cognitive stress if they do not have to push their limits in understanding the code when requested to implement new features or fix errors.
A glimpse into some patterns from the book
Most of the patterns are common patterns we are used to see in distributed systems. The book presents the pattern qualities, the context in which it is useful, the pattern trade-offs, and its quality aspects. But this presentation is done with a twist: it’s not always the same language we see for distributed back-end systems, and the focus is not on the same quality aspects.
But there are many parallels.
Vector clocks
An example of this is the pattern about vector clocks (chapter 7.9, In the messaging patterns sub language)
While timestamps generated with vector clocks are useful in logs, to analyse the order of occurred events, it is still a good idea to add system clock time to the log entries as well, as it makes analysing the logs easier.
The reminded me directly of the MongoDB paper from SIGMOD’19: Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB 2 and how they compare solutions then choose hybrid logical clocks. In this paper they explain the need of the happens-before semantic of Lamport clocks and vector clocks, but also want the clock to be bounded to physical time, because some MongoDB utilities like backup and recovery use a physical time reference.
It’s not a surprise, we see the same challenge to have logical clock for causality, but also human-time related clock for operations. The challenges are not exactly explained with the same terms, and the constraints are not exactly the same, but the parallel same logic is at play.
Separate real-time
The separate real-time pattern is the pattern that interested me the most during my first read. For an excellent reason: I see this as one of the best explanations of the data-plane/control-plane pattern, although the authors present is without even using the same language nor constraints directly.
The separate real-time pattern, once you remove all the context and details, is summarized like this:
There are always a machine control functionalities in a system.
To increase the productivity and operability of the machine, the system needs to offer high-level functionality such as a graphical user interface, diagnostics and so on.
The high-level functionalities’ behavior may compromise the real-time requirements of machine control functionalities.Therefore:
Divide the system into separate levels according to real-time requirements, for example into machine control and machine operator levels.
Real-time functionalities are located on the machine control level, and non-real-time functionalities on the machine operator level.
The levels cannot interfere with each other, as they use a message bus of other medium to communicate with each other.
Malfunction of a high-level functionality should not affect the availability of the machine, and under no circumstances should malfunction of a high-level functionality prevent the operator from using the machine.
Now, replace machine with data-plane and high-level functionalities with control-plane, and you get something which sounds very familiar. But we are (, well, I am) usually not able to explain it so clearly.
Our data planes are mission-critical. And our control planes are more complex, don’t have the same “real-time” requirements. They are essential. But if we have to choose, we’ll always prefer to see our control plane unavailable rather than the data plane, which would prevent our users from using our services.
I only scratch the surface. Seven pages and diagrams cover this pattern.
I hope it might give you an idea of how the different standpoint brings a new light on something familiar. It made me think about this again.
Wrapping this up
This quick write-up can hardly give an idea. The book covers 80 patterns after spending some chapters on higher-level topics like defining quality. But I hope it gives you enough to let you decide if you should read it or not.
My main takeaways are:
- a new view, from a different domain, on many common design patterns we see in distributed control systems.
- a very well articulated “language”: it’s not just a collection of patterns, but it’s also all the links between each of them, how some refine a higher-level pattern, or why some patterns are useful to complement the drawbacks of another one. I enjoyed the documented trade-offs. I also appreciated a lot the context explanations. A pattern is a solution to a specific kind of problem, for a specific set of constraints, and the authors do a great job at describing the context in which the pattern has been successful.
-
Designing Distributed Control Systems, a Pattern Language Approach, by Eloranta, Koskinen, Leppänen and Reijonen, published by Wiley in 2014. Book’s website ↩︎
-
Misha Tyulenev, Andy Schwerin, Asya Kamsky, Randolph Tan, Alyson Cabral, and Jack Mulrow. 2019. Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB In Proceedings of the 2019 International Conference on Management of Data (SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 636–650. DOI:https://doi.org/10.1145/3299869.3314049 ↩︎